
STT: What is Preferred Phrases feature and how to use it
Preferred phrases is a feature, available for 5th or newer generation of STT models and Speech Engine 3.32 or later.
This article explains what is the feature good for, how does it work internally and gives some tips for practical implementation.
What are preferred phrases
In the speech transcription tasks, there may be situations where similarly sounding words get confused, e.g. “WiFi” vs. “HiFi”, “cell” vs. “sell”, “eighty machines” vs. “eight tea-machines” etc.
Usually, the language model part of the Speech To Text does its job and prefers the correct word in the context of longer phrase or entire sentence:
| × I’m going to cell my car. | Hmmm, such sentence does not sound like common English… |
| √ I’m going to sell my car. | …but this one is very common. So this sentence is a clear winner. |
However, there are sentences which still make sense in both cases:
| √ My WiFi stopped working. | This sentence makes sense… |
| √ My HiFi stopped working. | …and this makes sense too. So which one is the winner?! |
And this is where the preferred phrases feature may come handy, allowing to prompt the speech transcription with phrases or words which are expected to appear in the utterance, thus increasing the chances of correctly transcribed words, increasing the overall transcription accuracy.
The intended application of this feature is mainly voicebots, i.e. in questions-driven dialogues, where the probable answers to each individual question are predictable and expected.
But it can help in other applications, too – e.g. when transcribing domain-specific audios, the frequently used domain-specific phrases can be boosted.
How preferred phrases work
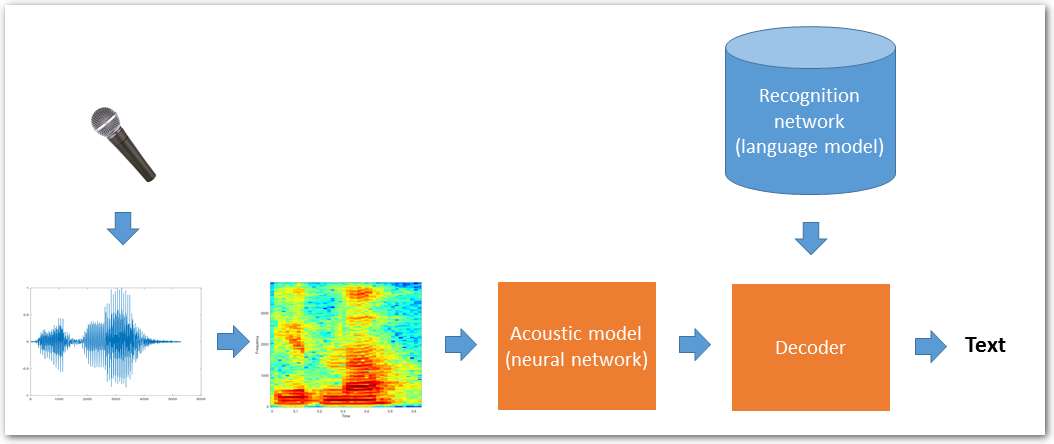
The picture below shows a simplified standard speech transcription process – the digitized speech signal spectrum is analyzed in the neural network acoustic model (which describes the pronunciations of a given language) and goes into a decoder. The decoder uses the information from acoustic model, combines it with information from language model recognition network (which describes the statistics about word grouping and sentences of a given language) and provides the transcription output.
(See the Speech To Text article for more details about speech transcription principles)
When using preferred phrases, we build additional language model from the preferred phrases and interpolate it in realtime with the generic language model:
P(word|history) = Pgeneric(word|history) + αPpreferred(word|history)
The preferred words and phrases are favored, while retaining the existing accuracy on common text.
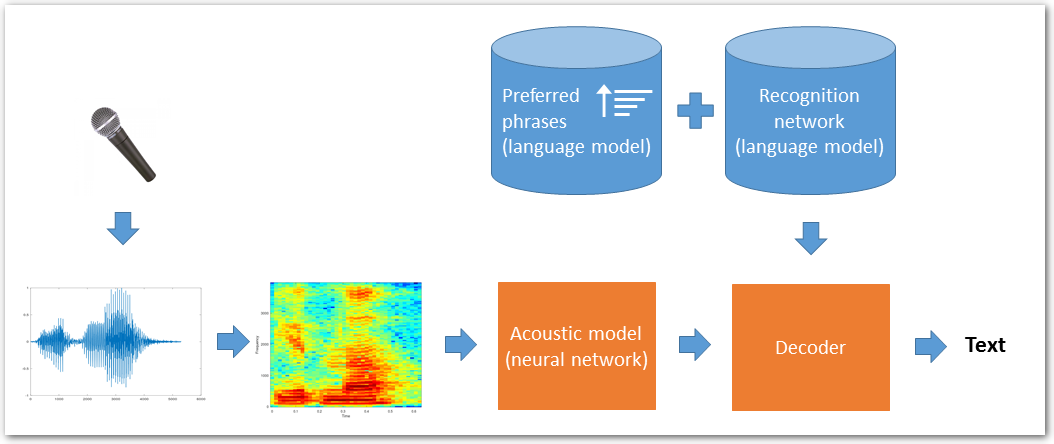
Preferred phrases in Speech Engine
Use POST /technologies/stt or POST /technologies/stt/input_stream call to start transcription with a list of preferred phrases.
To be precise, these actually serve two purposes, i.e. the input can contain either or both of:
phrasespart with preferred phrases themselves
(optionally also containing word classes tokens, if supported by the STT model)dictionarypart with words to be added to the STT language model
Preferred phrases is a list of words or phrases, which should be preferred by the transcription task.
STT analyzes all words from the supplied preferred phrases and checks its internal dictionary for existing pronunciations of the words. For words not found in the internal dictionary, STT automatically generates default pronunciation, based on the word graphemes (letters), following a particular language rules.
⚠ This may result – especially with foreign or non-native words – in incorrect or weird pronunciations, due to differences in pronunciations of certain graphemes in the transcription language. Therefore it is recommended to define words pronunciations in the dictionary part described below.
Complete list of the preferred phrases words and all their pronunciations is included in the transcription result for reference. This is useful for analysis of transcription errors and eventual tuning of words- or pronunciations definitions.
Starting with SPE 3.50, a word classes tokens can be used in preferred phrases.
Classes represent parts of speech that occur in spoken text, like names or addresses. Classes supported by a certain STT model can be listed using GET /technologies/stt/classes call. Different STT models support different classes, or don’t support classes at all. Empty list means no classes support in that model.
Using a class token in preferred phrases allows to improve transcription accuracy using a rather generic sentence that represents multiple variants of the sentence. Use the class name prefixed with $ as class token. Example:
My name is $first_name $surname and I live in $municipality at $street street.
The words to be added, listed in the dictionary part, specify words to be added to the STT language model.
This can be used e.g. for adding industry-specific terms, foreign or slang words, or to fine-tune pronunciations to accommodate to region- or country-specific language.
Specifying word pronunciations in this part is also mandatory for words using graphemes (letters), not belonging to the STT model’s native alphabet – e.g. German word like “grüßen” in Czech transcription – or even using different writing script like Cyrillic or Japanese Kana. Such words MUST be accompanied by a pronunciation definition, and that definition must use only phonemes supported by the STT model (i.e. the German word from the previous example would need to have pronunciation defined using Czech phonemes).
See also more details in Adding words to STT language model article.
Legacy preferred phrases (SPE 3.32 – 3.42) have a number of limitations:
- adding words to dictionary is not supported
- only words already known by the language model are allowed in preferred phrases
Phrases containing unknown words are ignored and a warning message is logged to SPE log. Therefore, to be able to use preferred phrases containing such ‘unknown words’, it’s necessary to- add these words to the language model first, using LMC – see STT Language Model Customization tutorial
- then perform the transcription using the customized STT model, specifying the preferred phrases in the
POST /technologies/sttorPOST /technologies/stt/input_streamREST call.
Note: The REST call body does not allow specifying custom pronunciations; they must be defined during the language model customization (LMC) step
- single-word phrases are preferred only in single-worded utterances… i.e. only in responses like “yes“, “no“, “drink“, “food“, etc… but not inside longer sentences like “I’d like to have a cold drink and a hot food“
- multi-word phrases are preferred anywhere in the utterances… i.e. phrases like “hot drink” or “good food” would be preferred in utterances like “Hot drink gets handy in cold winter days“, or “I’d like to have a hot drink“, or “I’d do anything for a hot drink, some good food and a warm bed“
Preferred phrases usage
IMPORTANT FACTS:
- use 5-words phrases at maximum – current STT generations do not support longer n-grams, so specifying longer phrases does not bring any benefit
- number of preferred phrases is not limited… but from practical perspective, using hundreds or thousands of phrases is questionable (such a huge number means “prefer basically anything what the speaker says”, which defeats its purpose)
- only 5th or newer STT generations support preferred phrases
Question: So, what to put in the preferred phrases list?
Short answer: A “hints” for the system… a phrases, which will help the system to recognize the correct terms and transcribe them correctly… i.e. those which are expected in the text, but get mixed-up with other words and transcribed incorrectly.
Longer answer: For example in voicebot implementation, the good candidates would be phrases extracted from utterances where the NLP layer failed to detect the correct intent (i.e. where the intent was either identified incorrectly, or was not detected at all).
Such utterances should be ideally manually analyzed, i.e. the transcription sent to the intent detector should be compared with the voicebot dialogue audio recording and the actual problematic part of the utterance (problematic phrase) should be identified. The problematic phrase could be then included in the list of preferred phrases – ideally, in phrases specific for the particular dialogue node; if that is not possible, then in generic list of preferred phrases for the entire voicebot dialogue.
Using (relevant parts of) some utterances from intent detector training set as preferred phrases could be also a good starting point.
TIP:
You may also find useful this article about finetuning end-of-utterance detection parameters.