
STT: Configuring word detection parameters for stream transcription
One of the improvements implemented since Speech Engine 3.24 is neural-network based VAD, used for word- and segment detection.
This article describes the segmenter configuration parameters and how they are affecting the realtime stream STT results.
The default segmenter parametrs are as shown below:
[vad.online_segmenter:SOnlineVoiceActivitySegmenterI] backward_extensions_length_ms=150 forward_extensions_length_ms=750 speech_threshold=0.5
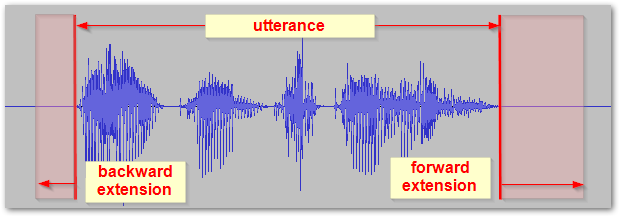
Backward- and forward extension are intervals in miliseconds, which extend the part of the signal going to the decoder.
Decoder is a component, which determines what a particular part of the signal contains (speech, silence, etc.). Based on that, decoder also decides whether segment has finished or not.
Unlike in file processing (where it’s possible to analyze any part of the file), in realtime processing we do not see into the future, i.e. the backward extension value actually says for how long the processing must be delayed (processing has to wait until that much input signal arrives) ⇒ increasing this value means that speech activity is detected with longer delay (e.g. means delayed barge-in detection in voicebot implementation).
The forward extension value basically means “add this much of a following signal to the processing, to check if the utterance maybe continues“. Decreasing this value means that even shorter pauses between words are detected as end of the segment. And vice versa – increasing this value means that longer pauses between words are not identified as end of a sentence.
Speech threshold is a unitless value specifying threshold between silence and speech.
Default middle value is −0.5. (yes, minus 0.5… the value in config file is set higher than the default value)
Lower values mean “even if there is not a real silence in the signal, consider it being a silence“, i.e. end of segment is detected more frequently.
Higher values mean “even if there is a silence in the signal, consider it being a speech“, i.e. end of segment is detected less frequently.
These values can be modified using a “user configuration file” – see What is a user configuration file article for additional details.
In short, create appropriately named user config file with modified parameters along the standard config file in <SPE directory>/bsapi/stt/settings directory and restart SPE – it will automatically read the values from the user config and override the ones from standard config.