
Measuring of a software processing speed – what is the FtRT (Faster than Real Time)
Faster than Real Time (FtRT) metric is developed for defining software performance reference point. Using this metric you can collect “benchmark” data of real processing speed for reviewed software, which should be found – and reproduced – on exactly defined HW.
Then, comparing various benchmarks result, you can compare performance of the specified software and its parts on different HW configurations. And vice versa – using the same metric, you can compare software from different vendors on the same HW configuration and for the same processing task.
We recognize two measurable metrics:
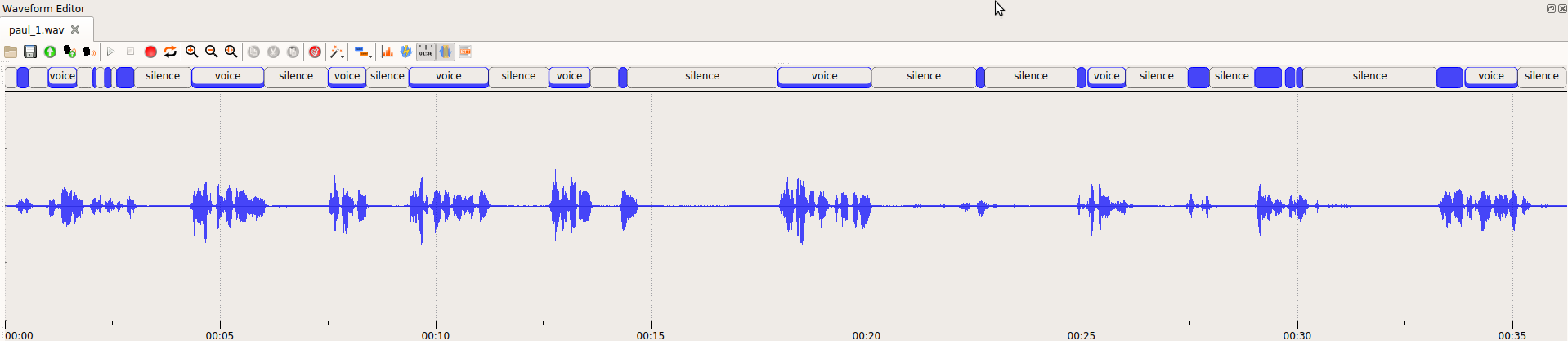
Audio based FtRT is calculated from actual audio in its original form, i.e. containing parts with spoken speech and also parts with silence or other non-speech signal (background noise, technical signals like ringing, DTMF tones, etc).
This metric is useful for finding performance on actual audio data coming into audio processing pipeline.
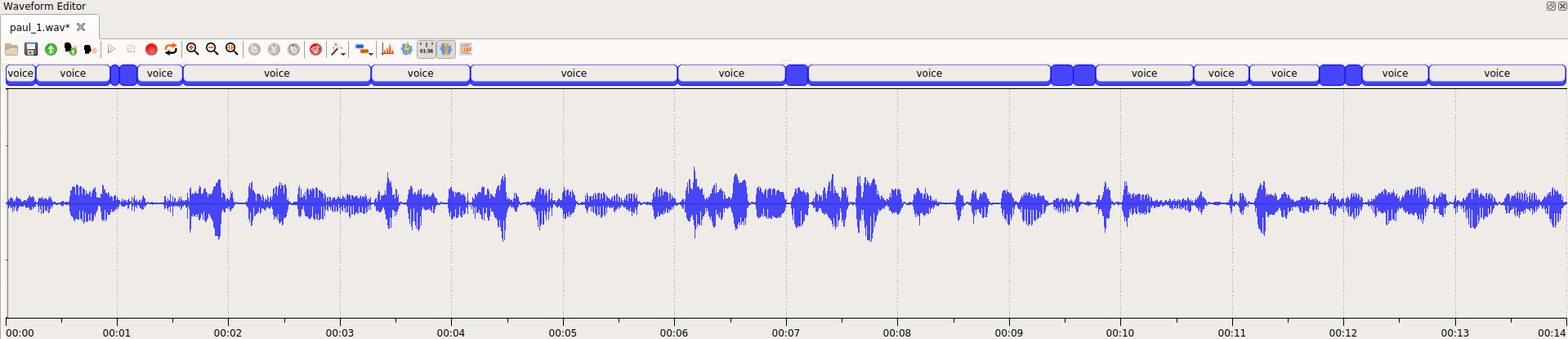
Net Speech based FtRT is conservative, purely technical number. It is calculated from only spoken speech data, i.e. with all non-speech parts (silence, noise, DTMF tones, etc.) removed.
This metric is useful for comparing technology performance on different hardware configuration, or comparing performance of the same type of technology produced by different vendors.
Calculation formula is very simple and is the same for both use-cases:
FtRT = audio_length[s] / processing_time[s]
Example
Original audio length in our example is 36 seconds. After stripping silence, it gets 14 seconds – this means that original audio contains 38% of net speech and 62% of silence.
Phonexia speech technologies analyze the entire recording, but pick only the speech segments for AI processing, i.e. the absolute processing time will be practically the same…
Creating voiceprint by Speaker Identification took:
0.20 second on Intel® Xeon® E5 2860 v4
0.168 second on Intel® Xeon® Platinum 8176
Let’s calculate:
Intel® Xeon® E5 2860 v4 performance:
FtRTaudio = 36/0.20 => 180 FtRT
FtRTnet_speech = 14/0.20 => 70 FtRT
Intel® Xeon® Platinum 8176 performance:
FtRTaudio = 36/0.168 => 214 FtRT
FtRTnet_speech = 14/0.168 => 83 FtRT
Conclusion
- FtRTnet_speech shows that Intel® Xeon® Platinum 8176 computing performance is better by ~17% compared with Intel® Xeon® E5 2860 v4
- FtRTaudio shows that real requirements for HW and its computing power are approx. 62% lower than traditional approach using FtRTnet_speech for audio dataset with similar ratio between speech and non-speech (silence) and it is proven by measuring it.
Best practices
Use FtRTaudio when calculating hardware sizing and scaling options, especially for installation built for mass data processing where each I/O matters. Don’t forget to test real data-sets (recordings) for statistical information like speech/non-speech ratio and so on. This approach can help you with budget calculation significantly.
Use FtRTnet_speech when comparing individual CPU performance using strict academic methodology using exact reference point.