
Keyword Spotting (KWS)
Phonexia Keyword Spotting (KWS) identifies occurrences of keywords and/or keyphrases in audio recordings. It can help you to get valuable information from huge quantities of speech recordings. You only need to specify the keywords or phrases you wish to find. This technology identifies all recordings with keyword occurrences and allows you to automatically route important recordings or calls to your experts.
Typical use cases
Call centers
- increase operator and supervisor efficiency by searching calls
- identify inappropriate expressions from operators
- check marketing campaigns with automatic script-compliance control
Mass media and web search servers
- index and search multimedia by keyword
- route multimedia files and streams according to their content
Security/defense
- maintain fast reaction times by routing calls with specific content to human operators
- search for specific information in large call archives
- trigger alarms immediately (online) when an event occurs
Technology
The Keyword Spotting technology is based purely on acoustics – there is no dependency on any dictionary – which means that any words can be searched for, even words in foreign languages.
Keyword Spotting works with a keyword list containing one or more keywords and optional threshold value and/or pronunciation variants of the keyword.
The number of keywords and pronunciations is not limited. However, the performance starts dropping with larger keyword lists – it’s recommended to use maximum of approx. 200 keywords – to clarify this statement:
The performance drop affects only processing using keyword lists without explicitly defined pronunciations. In such cases, the technology must create pronunciations internally in the background before starting the processing (see Pronunciations section below), which takes some time – the more pronunciationless keywords in the list, the longer delay occurs before the processing. When keyword list has pronunciations defined for each keyword, even thousands of defined keywords have no impact on performance.
Technology searches the recording and returns the list of found keywords, together with score and confidence for each found keyword. The score is a numerical expression of probability that word was said in a specified time frame.

Keywords
Keywords are not dependent on any dictionary. This allows to define specific, foreign or even nonexistent words like product names.
However, only allowed graphemes (symbols) from a supported list can be used to define keywords. This list can be easily obtained by Speech Engine and Command Line implementation.
TIP: If Keyword Spotting refuses a keyword and throws an error, check if the keyword uses only allowed graphemes.
Pronunciations
Keywords can be specified with, or without a pronunciation. If pronunciation is not specified, a default pronunciation is created internally.
This default pronunciation is either taken from a dictionary (if the keyword is found in dictionary), or generated automatically by grapheme-to-phoneme mechanism (for keywords not included in dictionary).
Pronunciations generated by the grapheme-to-phoneme mechanism are assigned a probability value, saying how confident the system is with the generated pronunciation. The value is a logarithm of probability from {-inf,0} interval.
Searched keywords may be spoken in the actual recordings using different pronunciation(s) than Keyword Spotting expects. This can be especially the case of product- or brand names, domain-specific words, misspelled words, incorrectly pronounced foreign words, etc. Therefore it’s highly recommended to explicitly specify pronunciation (or multiple pronunciation variants) for keywords.
The easiest way to specify a pronunciation is to start off with automatically generated pronunciation and modify it as needed.
Alternatively a Phoneme Recognizer (PHNREC) can be used to reveal (or “transcribe”) pronunciation directly from actual audio recording.
Phoneme Recognizer
Phoneme Recognizer (PHNREC) reveals the phoneme transcription of a specified audio recording, or its part. This can be used to get the actual pronunciation of a keyword or phrase as is actually spoken in the audio recording. This pronunciation can be then used in a keyword list for Keyword Spotting.
It’s a good idea to limit the start- and end time of Phoneme Recognizer transcription to only the time slot where the word or phrase of interest occurs.
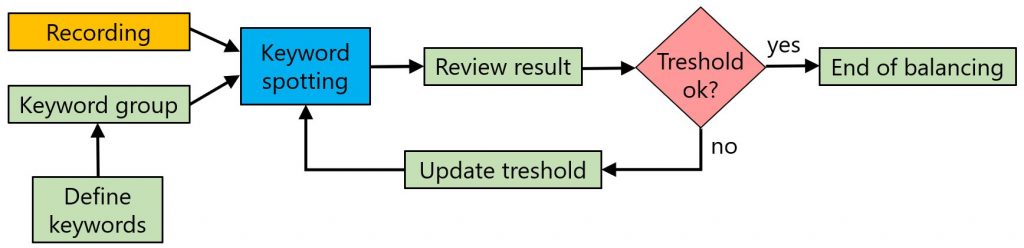
Thresholds
Threshold is a numeric value from {0,1} interval, limiting the output results. Only words with confidence exceeding the threshold are returned as result.
Command line implementation of Keyword Spotting supports global keywordlist-wide threshold and also optional thresholds for individual keywords (if used, threshold set on keyword level overrides the global threshold).
Speech Engine (SPE) supports only thresholds on keyword level.
Setting the right threshold is essential for getting relevant results and generally greatly increases the accuracy of the technology. However, setting the right threshold can get tricky due to the fact that it’s set on confidence, which is recalculated from raw score using a sigmoid function.
It’s strongly recommended to check details in Keyword Spotting results explained article.
Keyword list example
Here you can see an example of keyword list in JSON format for Speech Engine.
- a
contractkeyword, which is enabled (i.e. will be included in search), not specifying a confidence threshold (i.e. a default value0will be used – all detected occurrences will be reported), and not explicitly specifying any pronunciation (i.e. a default pronunciation, generated internally using grapheme-to-phoneme mechanism, will be used) - an
iPhonekeyword, which is disabled (i.e. will not be included in search), specifying a confidence threshold value0.6(i.e. that – if the keyword would be enabled – only occurrences with confidence equal or higher than the threshold will be reported), and not specifying explicitly any pronunciation (i.e. internally generated default pronunciation would be used) - a
MITkeyword, which is enabled, specifying a confidence threshold value0.4and two pronunciations, one of which is enabled and one is disabled (i.e. only the enabled one will be used in search)
{
"keywords": [
{
"name": "contract",
"enabled": true
},
{
"name": "iPhone",
"enabled": false,
"threshold": 0.6
},
{
"name": "MIT",
"enabled": true,
"threshold": 0.4,
"pronunciations": [
{
"phonemes": "eh m ay t iy",
"enabled": true
},
{
"phonemes": "m ih t",
"enabled": false
}
]
}
]
}
Languages Supported
List of supported KWS Languages