
LID: Terminology and adaptation
This article describes various ways of Language Identification adaptation.
Basic terminology
 |
Languageprint ( |
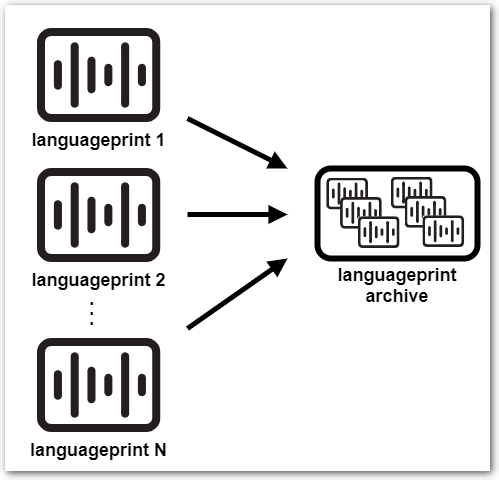 |
Languageprint archive ( SPE does not support creation of languageprint archives, they are supported as input only. |
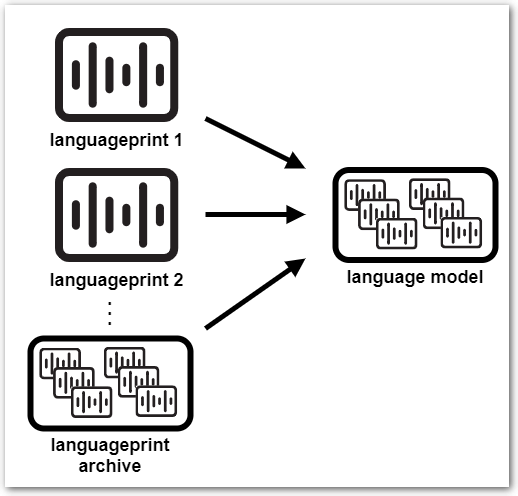 |
Language model – digital characteristics of a specific language NOTE about the word “model”: |
 |
Language pack – set of language models used for language identification |
⚠ All these entities MUST use the same technological model!
For example, languageprints created using model L4 can be combined into languageprint archive and/or language model only with languageprints created using model L4… and language pack for model L4 must consist only from language models created using languageprints/archives of model L4.
Adaptation types overview
- Creating new language model from your own audio files, to add new language not supported out-of-the-box
- at least 20 hours of audio is required, see requirements below
- Enhancing existing language model by adding your own audio files to existing built-in language
- at least 5 hours of audio is required, see requirements below
- Creating custom language pack consisting of your chosen set of languages, both pre-trained or created from your audio files
Audio recordings requirements
- Format: WAV, FLAC, RAW with linear coding 16bit/8bit, sampling rate 8kHz+
- Wide variety of speakers (50+) of various age and gender is required, to ensure rich variety of “language sounds”
- Only single language in the dataset
NOTE: mixing in a different language negatively affects the resulting recognition accuracy - Audio length: ideally between 1 and 5 minutes of speech signal
NOTE: it is not possible to train a language using just a few and long audio files (like 5 files, 1 hour each) - Acoustic channels should be as close as possible to channel of intended deployment
Adaptation using REST API (SPE 3.38 or newer)
SPE 3.38 and newer include LID adaptation tasks in REST API, which makes the adaptation significantly easier than in previous versions.
Creating language model
Language model can be created from languageprints (*.lp) extracted from audio files, or from pre-trained language prints archives (*.lpa), or from combination of both.
Combination of both .lpa and .lp is used when enhancing existing language model – the .lpa is the existing language model and the .lps are created from your audio files.
- Extract languageprints from you audio files
usingGET /technologies/languageid/extractlpendpoint - Create new (yet empty) language model
usingPOST /technologies/languageid/languagemodels/{name}endpoint - Upload languageprint- or languageprint archive file to the language model
usingPOST /technologies/languageid/languagemodels/{name}/fileendpoint- repeat this upload for all necessary files – e.g. when creating completely new language model from your own audio files, this would be hundreds or thousands of files (see audio requirements above)
More details are available in the REST API documentation: https://download.phonexia.com/docs/spe/#examples_languageid_create_lmodel
Creating language pack
- Get list of language models available for creation of your language pack
usingGET /technologies/languageid/languagemodelsendpoint - Create your custom language pack
usingPOST /technologies/languageid/languagepacks/{name}endpoint
More details are available in the REST API documentation: https://download.phonexia.com/docs/spe/#examples_languageid_create_lpack