
KWS: Results explained
This article aims on giving more details about Keyword Spotting outputs and hints on how to tailor Keyword Spotting to suit best your needs.
Scoring
Keyword Spotting works by calculating likelihood ratios (LR) that at a given spot occurs a keyword or just any other speech, and comparing those two likelihood ratios.
The following scheme shows Background model for anything before the keyword (1), the Keyword model (2) and a Background model of any speech parallel with the keyword model (3).
Models 2 and 3 produce two likelihoods – Lkw and Lbg (any speech = background).
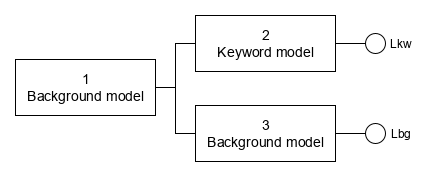
Raw score is calculated as log likelihood ratio (LLR): score = loge(Lkw/Lbg)
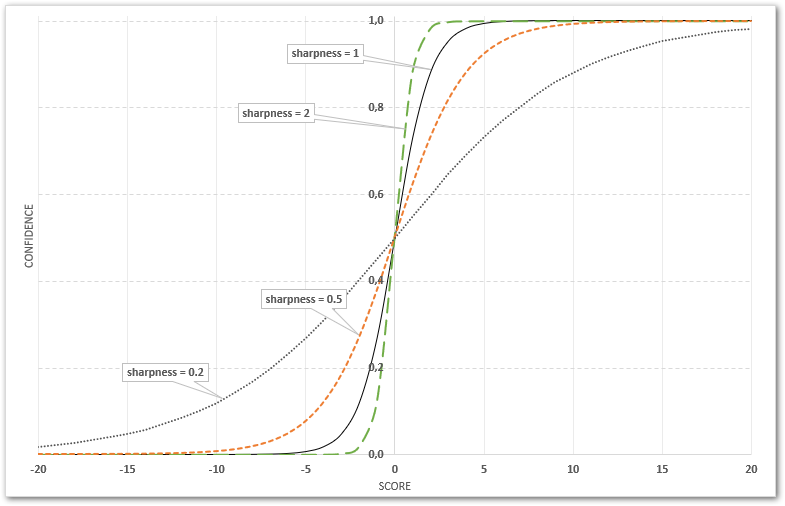
Confidence is calculated from the raw score using a sigmoid function:
![]()
![]()
where:
shift shifts the score to be 0 at ideal decision point (default is 0)
sharpness specifies how the dynamic range of score is used (default is 1)
Note:
It’s important to properly understand the correlation between score and confidence via the sigmoid function steepness, controlled by the sharpness value.
To get a better idea about the correlation, check this Microsoft Excel sheet demonstrating the sigmoid function: Score-to-Confidence.
Score-to-confidence conversion tuning
Starting with SPE/BSAPI 3.24 (October 2019) it’s possible to modify the confidence calculation using confidence_shift and confidence_sharpness values in user configuration file in [score_calib:SKeywordScoreCalibrationI] section.
User configuration file must have the same name as original configuration file, with added .usr extension, e.g. kws_en_us_5.bs.usr – see the What is a user configuration file article for more details.
Example of user configuration file:
[score_calib:SKeywordScoreCalibrationI] confidence_shift=0.0 confidence_sharpness=0.3
Results
Keyword Spotting results contain list of detected keywords, each keyword with a start- and end time of the time slot where keyword was detected, and a score and confidence.
Keyword is listed in the results with a numeric suffix. This number is a 0-based index of the detected pronunciation.
Start- and end time is in HTK units. 1 HTK unit is 100 nanoseconds, so dividing the times by 10000 gives the amount of milliseconds.
Score is log likelihood ratio from {-inf,+inf} interval.
Confidence is a probability from {0,1} interval. To convert it to percentage, multiply the confidence value by 100.
Example
This example of Keyword Spotting results shows:
- word
sale, detected at 2 places, pronounced differently (hence the _0 and _1 suffixes pointing to two different pronunciations defined in the keyword list)
While the system is pretty sure about the first occurrence (high score and confidence values), the second occurrence is probably a false detection (low score and confidence). - words
Brazilandmachine, both detected with rather high scores and confidences
If e.g. the word sale would be defined with a threshold value e.g. 0.20 in the keyword list, the second occurrence would not appear in results at all, since its confidence is lower than the threshold.
...
{
"channel_id": 0,
"score": 4.5108547,
"confidence": 0.9891304,
"start": 171400000,
"end": 175900000,
"word": "sale_0"
},
{
"channel_id": 0,
"score": -1.5344038,
"confidence": 0.17735027,
"start": 246900000,
"end": 251700000,
"word": "sale_1"
},
{
"channel_id": 0,
"score": 2.1896133,
"confidence": 0.89931285,
"start": 284100000,
"end": 291000000,
"word": "brazil_0"
},
{
"channel_id": 0,
"score": 0.9341812,
"confidence": 0.7179228,
"start": 294900000,
"end": 300600000,
"word": "machine_0"
}
...